

Ijraset Journal For Research in Applied Science and Engineering Technology
Product Based Sentiment Analysis Based on Deep Learning for Amazon Review
Authors: Amit Purohit, Dr. Pushpinder Singh Patheja
DOI Link: https://doi.org/10.22214/ijraset.2024.64089
Certificate: View Certificate
Abstract
The growth of E-commerce gave importance to customer needs and opinions which in turn gave rise to an important aspect of online shopping known as ‘Customer Reviews’. User reviews are customer suggestions and opinions about the product which helps other customers make decisions about the product. Such review systems form the backbone of E-commerce. Using machine learning approach for sentiment analysis helps in finding useful patterns and derives predictions which are important in decision making for improvement of overall products and customer satisfaction. E-commerce websites generate thousands of reviews about different products on their website Sentiment Analysis is the process of identifying, extracting, and studying subjective knowledge using Natural Language Processing (NLP). The significance of sentiment analysis in understanding user-generated content, particularly in the context of Amazon product reviews. Our aim is to analyze the Amazon Customer Review Dataset using Aspect based sentiment analysis with Deep Learning Techniques and to uncover statistical trends, which can be used to improve customer satisfaction .The research evaluates multiple machine learning algorithms using a large dataset of Amazon reviews where BERT achieving the highest accuracy. Also we compare overall accuracy of these algorithms using measures like precision and recall and f measure.
Introduction
I. INTRODUCTION
Sentiment analysis is an interdisciplinary field that includes psychology, sociology, natural language processing, and machine learning. Sentiment analysis has gained widespread acceptance in recent years, not just among researchers but also among businesses, governments, and organizations (Sánchez-Rada and Iglesias 2019), several recent surveys (Yousif et al. 2019; Birjali et al. 2021) authors has described the problem of sentiment analysis and suggested potential directions. Soleymani et al. (2017) and Yadav and Vishwakarma (2020) on sentiment classification have been published. Also the topic of detecting opinion spam and fraudulent reviews was investigated.
Additionally, In the work of Yue et al. (2019) and Liu et al. (2012) conducted research on the effectiveness of internet reviews. The Authors (Jain et al. 2021b) discuss machine learning applications that incorporate online reviews in sentiment categorization, predictive decision-making, and the detection of false reviews. In the work of Balaji et al. (2021) conducted a thorough examination of the several applications of social media analysis utilizing sophisticated machine learning algorithms. Authors present a brief overview of machine learning algorithms used in social media analysis (Hangya and Farkas 2017). The computational study of people's opinions, feelings, emotions, and attitudes towards things like products, services, issues, events, and subjects and their qualities is known as sentiment analysis or opinion mining.[1] Opinion Mining involves extracting opinions expressed by a considerable audience in a specific domain. This process aims to understand and analyze the sentiments or attitudes conveyed by individuals towards various subjects or aspects within that domain [12]. In general, a review's polarity can fall into one of three categories: neutral, positive, or negative [3]. There are various classification levels, including Document level, Sentence level, and Aspect or attribute level. The objective of this paper is to classify the positive and negative reviews of the customers over different electronic products using a correlation between ratings for the product for different categories within the Amazon electronics product.
1) Document-Level Sentiment Analysis
Document-level Sentiment Analysis reviews text and determines whether it has a positive or negative sentiment. It supports any sentiment-bearing text and determines the overall opinion of the document. Sentiment analysis at the document level assumes that each document expresses opinions on a single entity.
2) Sentence-Level Sentiment Analysis
Sentence level sentiment analysis determines if each sentence has expressed an opinion. This level distinguishes the objective sentences expressing factual information and subjective sentences expressing opinions. This time of sentiment analysis first identifies if the sentence has expressed an opinion or not, and then assesses the polarity of that opinion.
3) Aspect-Based Sentiment Analysis
Aspect based sentiment analysis refers to categorizing opinions by aspect and identifies the sentiment related to each. First, a system identifies the attitude targets mentioned in a given sentence. This process is known as aspect extraction. Once these aspects are identified, a system determines the attitude associated with each target in a process known as aspect-level sentiment analysis [6]. The proposed model adopts an aspect-based sentiment analysis (ABSA) method with BERT to extract user preferences from various aspects. ABSA is one of the core methods in natural language processing, extracting sentiments for different aspects embedded in the review text [18]. In addition, the proposed model utilizes an attention mechanism to capture unique attention weights for users and items. In this work, sentiment prediction is modeled as a supervised classification problem and is addressed using a deep learning architecture, based on BERT for sentiment analysis on amazon review, comparing with RFC,MNB and SVM and give the best accuracy by using Proposed Method.
A. BERT
Pre-trained language models are providing a context to words that have previously been learning the occurrence and representations of words from annotated training data. Bidirectional encoder representations from transformers (BERT) is a pre-trained language model that is designed to consider the context of a word from both left and right side simultaneously (Devlin et al., 2019). While the concept is simple, it improves results at several NLP tasks such as sentiment analysis and question and answering systems. BERT can extract more context features from a sequence compared to training left and right separately, as other models such as ELMo do (Peters et al., 2018). The left and right pre-training of BERT is achieved using modified language model masks, called masked language model (MLM). The purpose of MLM is to mask a random word in a sentence with a small probability. When the model masks a word it replaces the word with a token [MASK]. The model later tries to predict the masked word by using the context from both left and right of the masked word with the help of transformers. In addition to left and right context extraction using MLM, BERT has an additional key objective which differs from previous works, namely next-sentence prediction.
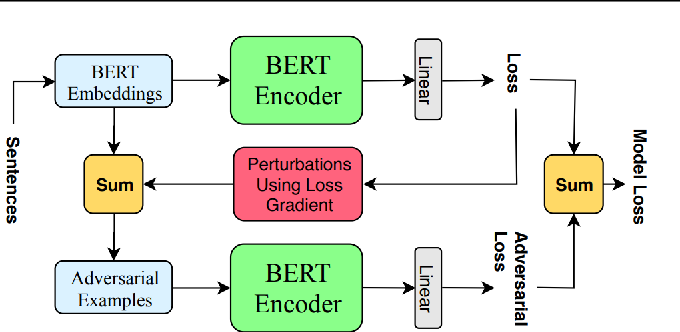
The main contributions of this study are as follows.
- Aspect Extraction method (tf-isf) is presented to detect aspect term of amazon product using different NLP techniques.
- To solve this task, a general classifier model is proposed, which uses the pre-trained language model BERT as the base for the contextual word representations. It makes use of the sentence pair classification model (Devlinet al., 2019) to find semantic similarities between a text and an aspect.
- Finally the Performance Measures of the proposed method by the classification metrics used for the sentiment analysis are Accuracy, Precision, Recall and F-measure.
Hence, product review opinions based on sentiment analysis effectively predict aspect terms; classify them based on polarity and extract specific products with increased accuracy and efficiency. The remainder of the paper has been organized as follows: Section 2 presents the recent literature; section 3 depicts the detailed description of the proposed methodology; section 4 discusses the implementation results; finally, section 5 concludes the paper. The contribution of this paper is a customer satisfaction model and a comparison of state-of-the-art methods. The main objectives of this paper are: Measuring customer sreview at Amazon, e.g. To achieve this, this study aims to collect the customer reviews from Amazon, e.g., and apply it to pre-processing like dealing with missing data and eliminating linkages, tags, numerical values, stop words, and more pre processing techniques Then applying Bert to predict sentiment on the Amazon dataset (a huge dataset of 50000 reviews). The experimental results were compared with other deep learning approaches such as bi-directional long-term memory (Bi-LSTM), support vector machines (SVM), Naive Bayes, and visualizing data and drawing conclusions. The proposed model using Bert was evaluated by F-measure with an accuracy of 88.4.
II. LITERATURE SURVEY
Aamir Rashid and Ching-yu Huang [10] The studies of this work understand and analyze the Amazon User Review Dataset with the help of different visualization techniques. These visualization techniques will help showcase various informative statistical trends which will provide us with insights about the Amazon Review system. These insights will help in exploring the possible improvements that can be done to satisfy the customers. Major work will involve empirical analysis for data understanding and exploration by taking into consideration, the various metrics related to the user reviews as opposed to sentimental analysis on the review text which aims at understanding the overall emotion of the reviews which has been done previously.. but it fails to obtain more products category and also compare amazon products with other electronics products from different companies and use advance visualization techniques to show more about the dataset
Basiri et al., [18] Sentiment analysis is becoming the main research issue in the field of natural language processing and data mining over the last decade. Deep neural network (DNN) models have recently been utilized to do sentiment analysis tasks, and the results have been encouraging. We present an Attention-based Bidirectional CNN-RNN Deep Model to extract both past and future contexts (ABCDM). ABCDM outperformed the competition on both long and short tweet polarity categorizations when compared to six previously suggested DNNs for sentiment analysis. The experiments used five reviews and three Twitter datasets. Using two bidirectional LSTM and GRU networks, past and future contexts are extracted as semantic representations of the input text. This method works well for extracting past context, however, it does not work well for predicting future context with semantic analysis because of the GRU technique's gradient issue.
Esha Tyagi* and Arvind Kumar Sharma[7] The primary aim of this paper is to apply Support Vector Machine (SVM) machine learning algorithm to classify the sentiments and texts for product reviews that analyses different datasets used for classification of sentiments and texts. Furthermore, various data sets have been utilized for training as well as testing and implementing the Support Vector Machine learning algorithm to find the polarity of the ambiguous sentiments. The primary objective of this paper is to implement Support Vector Machine (SVM) machine learning algorithm to classify the sentiments and texts for product reviews that analyses different datasets used for classification of sentiments and texts.; Finally, the Support Vector Machine classification algorithm is achieved high accuracy and found better one than others.
Pansy Nandwani1, Rupali Verma[8] The data must be processed as rapidly as generated to comprehend human psychology, and it can be accomplished using sentiment analysis, which recognizes polarity in texts. It assesses whether the author has a negative, positive, or neutral attitude toward an item, administration, individual, or location. In some applications, sentiment analysis is insufficient and hence requires emotion detection, which determines an individual’s emotional/mental state precisely. This review paper provides understanding into levels of sentiment analysis, various emotion models, and the process of sentiment analysis and emotion detection from text.
The most common datasets are SemEval, Stanford sentiment treebank (SST), international survey of emotional antecedents and reactions (ISEAR) in the field of sentiment and emotion analysis. SemEval and SST datasets have various variants which differ in terms of domain, size, etc. In this paper, a review of the existing techniques for both emotion and sentiment detection is presented.
Dionis López, Fernando Artigas?Fuentes[10] a novel aspect sentiment classification approach is proposed. Our approach combines a transformer deep learning technique with a continual learning algorithm in different domains. The input layer used is the pretrained model Bidirectional Encoder Representations from Transformers. The experiments show the efficacy of our proposal with 78 % F1?macro. Our results improve other approaches from the state?of?the?art. The LLA reduces catastrophic forgetting in the multi?domain context, and it is a novel approach in the ABSA context. Although the dataset’s order in????luence on the learning process has been evaluated, it is necessary to deepen these experiments.
Aziz et al, [17] Sentiment analysis is a technique for computationally identifying and categorizing opinions expressed in a piece of text, especially to determine whether the writer's attitude toward a certain subject is negative, positive, or neutral. Many researchers have proposed novel sentiment categorization methods, especially those based on supervised machine learning (ML). However, there is a lack of research in Cross-Domain Sentiment Analysis that has shown positive results at the moment.The purpose of this study was to examine how well the ML approaches described performed in the Single Domain while replacing feature selection procedures and running tests. MNB, SVM-LK, and SGD were the most reliable ML techniques. Although it takes significantly less time to complete the analysis, TF-IDF is preferable to frequency terms for feature selection (reduce more than 60 percent) SVM-capabilities RBF's produced strong results, particularly for less well-known domain knowledge.
III. PROPOSED METHODOLOGY
In our proposed approach and working of the system, first we extract reviews from the Amazon and identify aspects term by detecting noun phrases and several preprocessing techniques including tf-isf [13]. After finding aspects, we do sentiment analysis of words surrounded by those aspects, and assign score to each aspect and then we trained our model for the polarity of the review. The proposed sentiment analysis is based on BERT on Amazon Review. In this section, the stages of the proposed model, including data collection, data exploration, data preprocessing, feature extraction, training model, and evaluation metric, are presented in Fig.1.
A. Propose Model
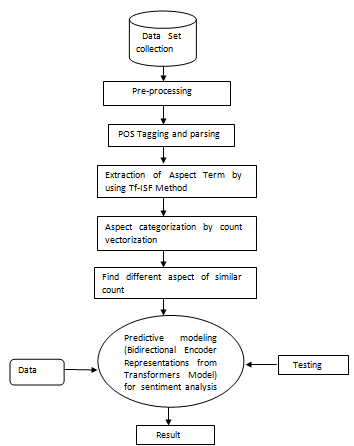
B. Data Set Collection
Data Collection Data is the most valuable item in the world now, and getting it is not as easy as possible. Amazon provides millions of data from their users' reviews of their products, so we relied on Amazon's review data set to train and evaluate our model. We collected a dataset from Kaggle which has a total of 35000 records this dataset is a collection of different review manufacturer product for training and testing. These are more than 30 columns such as product id, category, sub-category, review title, review text, reviewer name, etc. raw dataset has a lot of null values also data and price format were not correct, there were also outliers and noise in the dataset.
C. Loading the Dataset
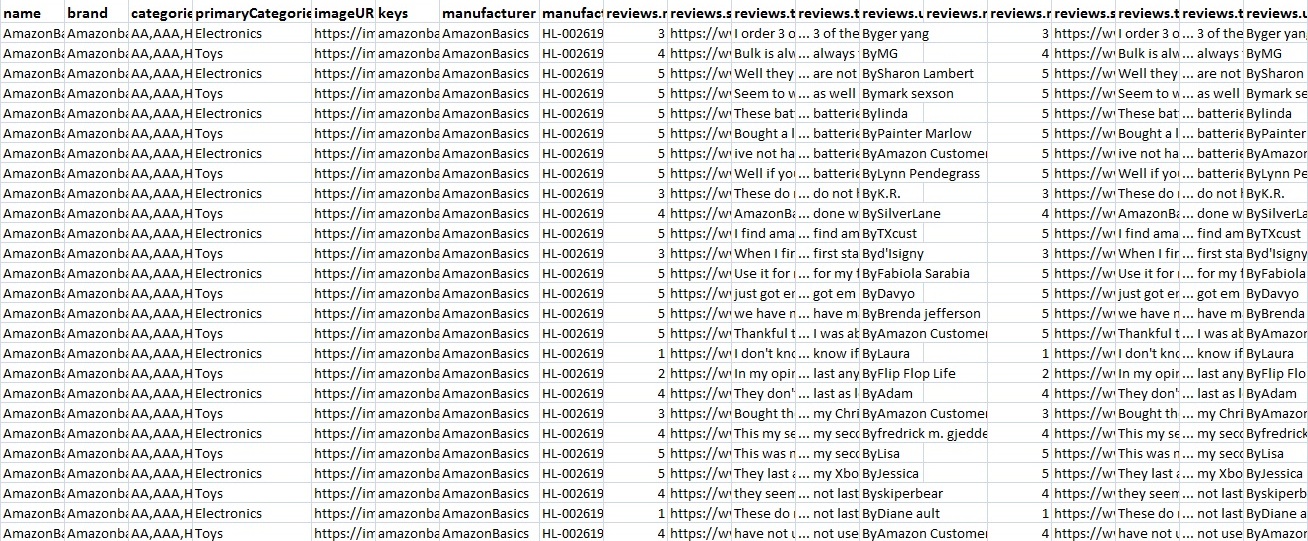
Data Collection Data is the most valuable item in the world now, and getting it is not as easy as possible. Amazon provides millions of data from their users' reviews of their products, so we relied on Amazon's review data set to train and evaluate our model. We collected a dataset from Kaggle which has a total of 35000 records this dataset is a collection of different review manufacturer product for training and testing. These are more than 30 columns such as product id, category, sub-category, review title, review text, reviewer name, etc. raw dataset has a lot of null values also data and price format were not correct, there were also outliers and noise in the dataset. Fig. 1 shows a few columns from the Original Amazon consumer product review dataset. We can see that in a few columns Values are null and in the wrong format Data file in JSON format is converted into CSV file.
Actual Amazon customer review sample

• Summary: The title of the review
• Review text: The actual content of the review.
• Rating: User rating of the product on a scale of 1 to 5.
• Summary: The number of people who found the review useful. These aspects will help us understand and analyze the reviews to derive insights.
D. Pre-processing
Our data pre-processing steps aim at transforming the raw input data into a format that Our Model can understand. This involves carrying out two primary steps. First, creating input examples using the constructor provided by BERT. The constructor accepts three main parameters, which are text a, text b, and label. Text a is the text that we want the model to classify, which in this case, is the collection of product reviews without their associated labels. Text b is used if we are training a model to understand the relationship between sentences, for example sentence translation and question answering. This scenario hardly applies in our work, so we just leave text b blank. Label has labels of input features. In our case, label implies sentiment polarity of every product review. Refer to original paper [4] for more details about this step. Then, we conduct the following pre-processing steps.
- Lowercase our text, since we are using the lowercase version of BERT.
- Tokenize all sentences in the reviews. For example,”this is a very good product” to”this”, ”is”, ”a”, ”very”, ”good”, ”product”.
- Break words into word pieces.
- Map our words to indexes using a vocab file that is provided by BERT.
- Adding special tokens: [CLS] and [SEP], which are used for aggregating information of the entire review through the model and separating sentences respectively.
- Append index and segment tokens to each input to track a sentence that a specific then taken as inputs to our model in addition to the reviews labels.
1) Tokenization
Tokenization is the process of breaking down a text document into smaller tokens, like words or phrases, for easier analysis and processing by computers. It is crucial in Natural Language Processing (NLP) tasks to make machines understand and interact with natural language. The tokenization approach depends on the task and granularity level. It separates a string sequence into tokens such as keywords, words, symbols, phrases, and other topics called tokens. In time, tokens can be phrases, words, or entire sentences. Furthermore, some characters, such as punctuation marks, were removed in the tokenization phase [12].
2) Removal of Stop Words
Stop words are often used in text analysis to focus on more meaningful words that contribute to understanding content and pattern identification. The decision to remove stop words depends on the task and data properties. Stop words are usually non-semantic words like articles, prepositions, conjunctions, and pronouns. Words such as ‘the’ and ‘a, are articles, and pronouns such as ‘it’ ‘we’ and ‘you’ provide little or no information about sentiment [14]. Therefore, remove those words from the dataset to improve the training and testing efficiency of the machine learning classifiers.
3) Lemmatization
Lemmatization is a method of lexicon normalization that reduces words to their root form based on their meaning and context. It uses vocabulary to highlight dictionary value and morphological analysis to emphasize word formation. This preserves the meaning and context of the sentence being normalized. The final step is the removal of non-words, such as symbols, numbers, and punctuation marks, to simplify the text. Lexicon normalization converts high-dimensional features into low-dimensional space features for machine learning models. Words that occur more than once must be normalized to avoid textual noise.
4) Feature Extraction
TF-IDF is the basic building blocks for many machine learning algorithms [10]. TF-IDF stands for Term Frequency and Inverse Document Frequency are two closely inter related metrics for searching and identifying the relevancy of a given word to the document. Separate Term Frequency and Inverse Document Frequency values are associated with each word. TF∗IDF represents the products of weightage of individual score. High TF∗IDF score represents the rare occurrence. TF represents the Term Frequency; IDF represents the importance of the term throughout the entire document.
The Term Frequency-Inverse Document Frequency (TF-IDF) algorithm, the most popular term weighting scheme [10], is used to numerically assess the relevance of a word in a document. The score frequency given to a word with TF-IDF determines the importance of a word for the document(s) based on the frequency of the word. The formulas used to calculate the TF-IDF score step-by-step are:
tf(w,d)=log(1+fw,d) (1)
idf(w,D)=log(Nf(w,D)) (2)
tfidf(w,d,D)=tfw,d∗idf(w,D) (3)
a) Algorithm for Keywords Extraction in TF-ISF
Step 1: Take Amazon review comments as input
Step 2: Remove stop words from input text using Pre-processing
Step 3: Check the input words in noun morph and if necessary perform noun stemming.
Step 4: Calculate TF-IDF score of each remaining word using TF-ISF measure
Step 5: Take high TF-ISF scores as candidates for keywords.
b) Training Model
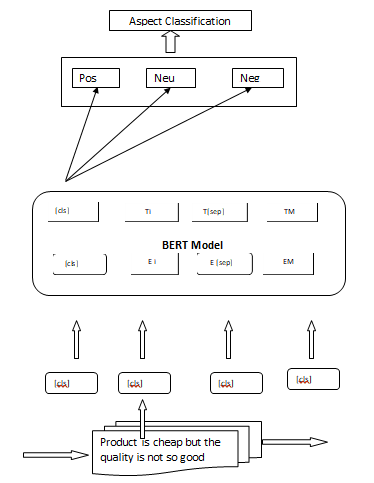
Product Review
IV. EVALUATION METRICS
Similar to evaluation metrics used in [9], we use the accuracy performance measure to evaluate the performance of our model and compare it with other models. Performance Indicators
1) Precision
Precision is a measure of correctness that explains how many total positive predictions are positive. It is determined by dividing the total number of predicted positives by the total number of classified positives. The precision level should be high for a well-performed model. Precision is defined as follows:
Precision = TP / (TP + FP)
Where TP is true positive and FP is false positive.
2) Recall
A recall is the ratio of all positively classified classes that were correctly identified to all positively classified classes or the number of classes with a positive outcome that are correctly predicted. A good model should have a high recall rate. Recall is defined as follows:
Recall = TP/ (TP + FN),
where FN is false negative.
3) F1 Measure
A high F1-score indicates high precision and recall because the score contains information about these two variables. It is defined as follows:
F1 = (2 × Precision × Recall)/(Precision + Recall).
4) Accuracy
The average of the square of the difference between the data’s original and anticipated values is used to calculate the mean square error. As the value goes down, the model’s performance gets better.The standard deviation of the errors that result from making a prediction on a dataset is known as the root mean square error. However, when determining the model’s accuracy, the value’s root is considered. As the value goes down, the model’s performance gets better.
5) Result Review
Various methods for extricating the typical features from the consumer reviews and a different point of view for assigning sentiment to review sentences have been expressed. Our speculation is that customer specified text reviews into positive and negative reviews by enhancing the classification performance. We have used different classifiers performance metrics like precision, recall, F1-Measure and Accuracy. Performance of various algorithms along with BERT model is shown in Table, in which the results of performance metrics of BERT are comparatively higher than other Machine Learning algorithms. BERT yields higher accuracy of 94.18%.
Table. Comparative analysis of NB, SVM, LSTM, BERT.
|
Features & Model |
Precision |
Recall |
F1-Measure |
Accuracy |
|
NB |
79.32 |
73.57 |
69.32 |
80.12 |
|
SVM |
80.68 |
82.31 |
81.26 |
83.33 |
|
LSTM |
80.57 |
79.38 |
82.34 |
84.97 |
|
BERT |
88.09 |
86.22 |
89.41 |
94.18 |
Conclusion
This paper proposes a simple and easy way to incorporate a review system that takes the comments in the form of strings and outputs scores that can be used to plot a graph and compute the review. As shown in this paper, the BERT networks are the most suitable for product based sentiment analysis on basis of Amazon dataset. Based on the results of the evaluation datasets, we can conclude that BERT performs very well, with an accuracy of 94.1% with the help of Aspect based Feature Extraction. As can be seen clearly from the previous confusion matrices, the BERT network performs both accurate results for negative and positive classes. The results show that the proposed method is compared with other existing techniques and the proposed outperforms all the other existing techniques. In future, this work will be extended with enhanced techniques such as optimization algorithms, deep learning and multilingual sentiment analysis to improve convergence rate and computational efficiency.
References
[1] “A Comprehensive Review Of Recent Developments In Aspect-Based Sentiment Analysis “(2023)Mrs. Simran N.Maniyar Research Scholar, Department Of Computer Science And It, [2] “Hierarchical Enhancement Framework For Aspect-Based Argument Mining” Yujie Fu1, Yang Li2, Suge Wang1,3_, Xiaoli Li4, Deyu Li1,3, Jian Liao1, Jianxing Zheng1 [3] “Hybrid Quantum-Classical Machine Learning For Sentiment Analysis” Abu Kaisar Mohammad Masum, Anshul Maurya, Dhruthi Sridhar Murthy, Pratibha, And Naveed Mahmud Electrical Engineering And Computer Science [4] “Aspect-Based Sentiment Analysis Using Machine Learning And Deep Learning Approaches “International Journal On Recent And Innovation Trends In Computing And Communication Issn: 2321-8169 Volume: 11 [5] “A Deep Learning Approach To Aspect-Based Sentiment Prediction” Maglogiannis Et Al. (Eds.): Aiai 2020, Ifip Aict 583, Pp. 397–408, 2020. [6] “An Attentive Aspect-Based Recommendation Model With Deep Neural Network” Sigeon Yang1, Qinglong Li1, Haebin Lim1, And Jaekyeong Kim1,2 Department Of Big Data Analytics, Kyung Hee University, Seoul 02447, South Korea School Of Management, Kyung Hee University, Seoul 02447, South Korea(2020) [7] ”Sentiment Analysis Of Product Reviews Using Support Vector Machine Learning Algorithm” Esha Tyagi* And Arvind Kumar Sharma [8] A Review On Sentiment Analysis And Emotion Detection From Text Accepted: 10 July 2021 / Published Online: 28 August 2021 8 , Journal Of Big Data Indian Journal Of Science And Technology, Vol 10(35), Doi: 10.17485/Ijst/2017/V10i35/118965, September 2017 [9] “Electronic Product Feature-Based Sentiment Analysis Using Nu-Svm Method” Article In International Journal On Information And Communication Technology (Ijoict) • March 2016 [10] “A Model Of Continual And Deep Learning For Aspect Based In Sentiment Analysis” Submitted: 10th January 2023; Accepted: 18th February 2023 [11] “Aspect Level Sentiment Classification Sentiment Analysis On Consumer Reviews Of Amazon Products” Article In International Journal Of Computer Theory And Engineering • January 2021 Doi: 10.7763/Ijcte.2021.V13.1287 [12] “Feature Selection And Polarity Classification Using Machine Learning Algorithms Nb & Svm “Smita Bhanap A Dr. Seema Babrekar B [13] “Subjectivity Analysis For Aspect-Based Sentiment And Opinion Detection Of Youtube Product Reviews” December 19th, 2023 [14] Birjali, Marouane, Mohammed Kasri, And Abderrahim Beni-Hssane. \"A Comprehensive Survey On Sentiment Analysis: Approaches, Challenges, And Trends.\" Knowledge-Based Systems 226 (2021) [15] Wankhade, Mayur, Annavarapu Chandra Sekhara Rao, And Chaitanya Kulkarni. \"A Survey On Sentiment Analysis Methods, Applications, And Challenges.\" Artificial Intelligence Review (2022) [16] Alaparthi, Shivaji, And Manit Mishra. \"Bert: A Sentiment Analysis Odyssey.\" Journal Of Marketing Analytics 9.2 (2021): 118-126. [17] Bhargava, Prajjwal, Aleksandr Drozd, And Anna Rogers. \"Generalization In Nli: Ways (Not) To Go Beyond Simple Heuristics.\" Arxiv Preprint Arxiv:2110.01518 (2021). [18] Sajid, Muhammad, Et Al. \"Impact Of Land-Use Change On Agricultural Production & Accuracy Assessment Through Confusion Matrix.\" (2022). [19] Zerrouki, Kadda, Reda Mohamed Hamou, And Abdellatif Rahmoun. \"Sentiment Analysis Of Tweets Using Naïve Bayes, Knn, And Decision Tree.\" Research Anthology On Implementing Sentiment Analysis Across Multiple Disciplines. Igi Global, 2022. 538-554. [20] Li, Cai, Et Al. \"China’s Public Firms’ Attitudes Towards Environmental Protection Based On Sentiment Analysis And Random Forest Models.\" Sustainability 14.9 (2022): 5046. [21] Hidayat, Tirta Hema Jaya, Et Al. \"Sentiment Analysis Of Twitter Data Related To Rinca Island Development Using Doc2vec And Svm And Logistic Regression As A Classifier.\" Procedia Computer Science 197 (2022): 660-667. [22] Li, Wei, Et Al. \"Bieru: Bidirectional Emotional Recurrent Unit For Conversational Sentiment Analysis.\" Neurocomputing 467 (2022): 73-82. [23] P. Karthika, R. Murugesari, R. Manoranjithem, Sentiment Analysis Of Social Media Network Using Random Forest Algorithm. Department Of Computer Science And Engineering, Kalasalingam Academy Of Research And Education, (2019). Https://Ieeexplore.Ieee.Org/Document/8951367 [24] Mamta, Ekbal, A., Bhattacharyya, P., Srivastava, S., Kumar, A., And Saha, T. (2020). Multi-Domain Tweet Cor- 589 Pora For Sentiment Analysis: Resource Creation And Evaluation. In Lrec. [25] Neha Nandal, (2020). Machine Learning Based Aspect Level Sentiment Analysis For Amazon Products. [26] Aashutosh Bhatt, Ankit Patel, Harsh Chheda, Kiran Gawande, (2015). Amazon Review Classification And Sentiment Analysis. [27] Alexander Wallin, (2014). Sentiment Analysis Of Amazon Reviews And Perception Of Product Features. [28] Tanjim Ul Haque, Nudrat Nawal Saber, Faisal Muhammad Shah, (2018). Sentiment Analysis On Large Scale Amazon Product Reviews. [29] Polignano, M., Basile, P., De Gemmis, M., Semeraro, G., And Basile, V. (2019). Alberto: Italian Bert Language Understanding Model For Nlp Challenging Tasks Based On Tweets. In Proceedings Of The Sixth Italian Conference On Computational Linguistics (Clic-It 2019), Volume 2481. Ceur [30] Bianchi, F., Nozza, D., And Hovy, D. (2021). Feelit: Emotion And Sentiment Classification For The Italian Language. In Proceedings Of The Eleventh Workshop On Computational Approaches To Subjectivity, Sentiment And Social Media Analysis, Pages 76–83, Online, April. Association For Computational Linguistics. [31] Barbieri, F., Basile, V., Croce, D., Nissim, M., Novielli, N., And Patti, V. (2016). Overview Of The Evalita 2016 Sentiment Polarity Classification Task. In Proceedings Of Third Italian Conference On Computational Linguistics (Clic-It 2016) & Fifth Evaluation Campaign Of Natural Language Processing And Speech Tools For Italian. Final Workshop (Evalita 2016). [32] Vote Recommendation System Using Aspect Based Machine Learning Approach Article In International Journal Of Engineering And Advanced Technology • August 2020 Doi: 10.35940/Ijeat.F1311.089620
Copyright
Copyright © 2024 Amit Purohit, Dr. Pushpinder Singh Patheja. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET64089
Publish Date : 2024-08-27
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online